
热议!DeepSeek V3.1惊现神秘「极」字Bug,模型故障了?
热议!DeepSeek V3.1惊现神秘「极」字Bug,模型故障了?上周三,DeepSeek 开源了新的基础模型,但不是万众期待的 V4,而是 V3.1-Base,而更早时候,DeepSeek-V3.1 就已经上线了其网页、App 端和小程序。
来自主题: AI资讯
8811 点击 2025-08-26 19:44
 搜索
搜索
上周三,DeepSeek 开源了新的基础模型,但不是万众期待的 V4,而是 V3.1-Base,而更早时候,DeepSeek-V3.1 就已经上线了其网页、App 端和小程序。
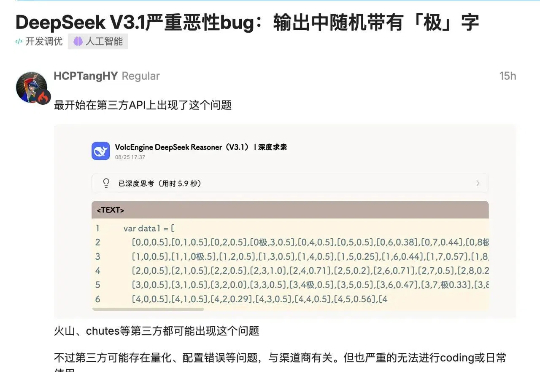
一早起来,看到群里炸了锅!主角是我们备受期待的 DeepSeek V3.1 模型。有用户反馈,该模型在生成文本时,会毫无征兆地随机插入“极”这个汉字(繁体简体都会)
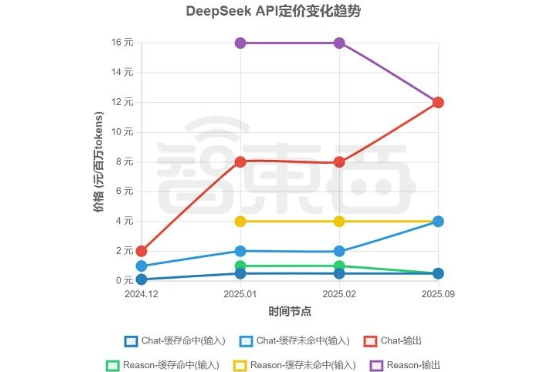
DeepSeek涨价了。 智东西8月23日报道,8月21日,DeepSeek在其公众号官宣了DeepSeek-V3.1的正式发布,还宣布自9月6日起,DeepSeek将执行新价格表,取消了今年2月底推出的夜间优惠,推理与非推理API统一定价,输出价格调整至12元/百万tokens。这一决定,让使用DeepSeek API的最低价格较过去上升了50%。
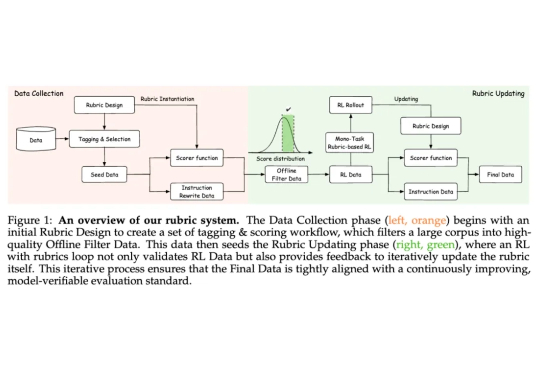
蚂蚁技术研究院联合浙江大学开源全新强化学习范式 Rubicon,通过构建业界最大规模的 10,000+ 条「评分标尺」,成功将强化学习的应用范围拓展至更广阔的主观任务领域。用 5000 样本即超越 671B 模型,让 AI 告别「机械味」。

继Kaggle Game Arena的淘汰赛后,国际象棋积分赛成果出炉!OpenAI o3以人类等效Elo 1685分傲视群雄,而Grok 4和Gemini 2.5 Pro紧随其后。DeepSeek R1和GPT-4.1、Claude Sonnet-4、Claude Opus-4并列第五。
DeepSeek V3.1发布后,一则官方留言让整个AI圈都轰动了,新的架构、下一代国产芯片,总共短短不到20个字,却蕴含了巨大信息量。

今天下午,DeepSeek 官方正式发布 DeepSeek-V3.1。相比于前天只在用户群里通知,今天新增了模型升级点、榜单成绩、model card,huggingface 上现在也可以下载模型文件了。
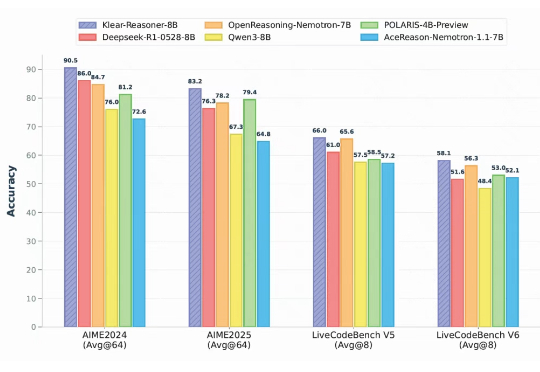
在大语言模型的竞争中,数学与代码推理能力已经成为最硬核的“分水岭”。从 OpenAI 最早将 RLHF 引入大模型训练,到 DeepSeek 提出 GRPO 算法,我们见证了强化学习在推理模型领域的巨大潜力。
软件+硬件的全链路国产 AI 体系来了? 这几天,不论国内国外,人们都在关注 DeepSeek 发布的 V3.1 新模型。
自从 GPT-5 发布后,DeepSeek 创始人梁文锋就成了 AI 圈最「忙」的人。